Yeedu is a re-architected, high performance Spark engine that runs the same workloads at a fraction of the cost. Run existing code with zero changes — just get faster results and smaller bills.
Our Turbo Engine accelerates Spark with zero impact on your codebase. For dramatic performance improvements and cost savings.

Uses vectorized query processing with SIMD instructions to accelerateCPU-bound tasks 4-10X faster than standard Spark.

Packs more jobs within existing CPU cycles, maximizing resource utilizationwhere regular Spark leaves CPUs underutilized.

Your existing Spark code executes faster with no refactoring,for immediate ROI with no development effort.
Yeedu is how Cloudera and Databricks users can get maximum performance with predictable costs.
.png)

.png)
Everything your team needs to build, deploy and scale — faster than ever
Interactive development environment. Simple and familiar, Jupyter notebook like web-based interface. for writing and running code in Python, SQL, and Scala.
Compute clusters scale up/down based on workload metrics. Optimal resource usage thus minimizing wastage with auto-scale, auto-start and auto-stop
Enterprise-grade access governance. Seamless management of multiple tenants with access controls for compute clusters and workloads.
Complete visibility of usage. Single pane of glass to monitor usage across different tenants, clusters, use-cases.
Quick deployment of ML models and Python FunctionsFew clicks to deploy and serve ML models and Python functions via REST APIs.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.

International standard for managing information security.

International standard for quality management.

US law regulating the privacy and security of protected health information.

Framework for assessing a service provider's controls for customer data security.

European regulation protecting the privacy and rights of EU citizens' data.
Yeedu offers a tiered licensing model, with monthly fees starting at $2,000. Pricing increases with higher usage tiers, ensuring scalability and cost efficiency.
Yeedu supports open-source Apache Spark, and your PySpark and Scala jobs can be migrated “As-Is” to Yeedu. It also supports Python 3+.
No, Yeedu supports open-source Apache Spark. Jobs can be written in PySpark or Scala and migrated to other platforms as needed, ensuring flexibility.
Yeedu has helped enterprises cut costs by an average of 60%. To evaluate potential savings, you can start by onboarding a sample workload.
Yes, Yeedu can run any Python job written in Python 3+, including those using popular modules like pandas.
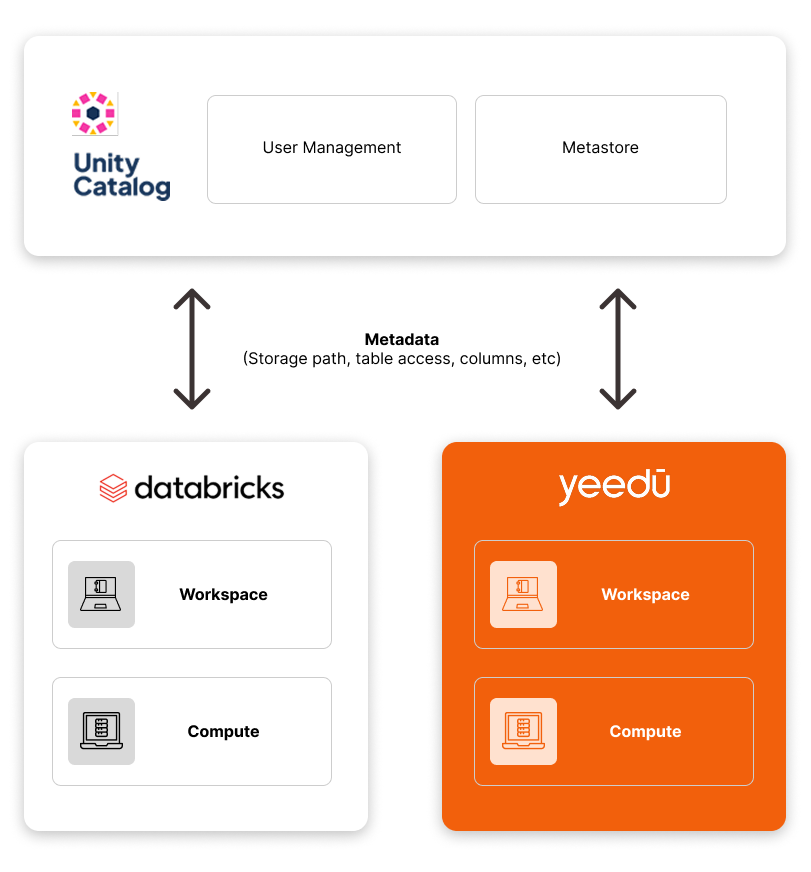
Yeedu is a data platform that creates and runs data processing workloads like Databricks and Cloudera. However, Yeedu works well with Databricks and Cloudera's governance setup, so rather than a full workload migration, customers can start migrating high-cost workloads to Yeedu to maximize their cost savings. Over time, more workloads can be migrated as customers see value.
Yeedu supports Python, Scala, and Java jobs and provides optimal performance for Spark workloads. It is designed to enhance Spark application efficiency and cost savings.
No, there are no minimum thresholds. Yeedu delivers noticeable cost savings when a mix of low, medium, and heavy workloads are run on the platform.
Yeedu runs entirely within your cloud account, under your firewall. You do not need to export data outside your environment.
Existing Python, Scala, and Java jobs can be onboarded to Yeedu by uploading the code files. If your jobs are in notebook format, they can be easily migrated to Yeedu’s notebook editor and executed seamlessly.
If you don't see your question, please reach out to us
Eliminate wasteful spending, ship efficient code, and innovate profitably — all in one platform.